


Understanding AIF Services for Dynamics AX Integration
As a solution architect I am often involved in helping clients integrate Dynamics AX with other Line-of-business applications. When discussing the integration options for AX the question of AIF Document Services vs. AIF Custom Services inevitably comes up. In this article I will attempt to describe the differences and provide some guidance for the appropriate use of each option.
Note: In the Article, "System architecture [AX 2012]" on Microsoft technet (http://technet.microsoft.com/en-us/library/dd362112(AX.60).aspx) you will find this statement. "Use services and AIF to interact with the Microsoft Dynamics AX application. We recommend that you not use .NET Business Connector for integration with the Microsoft Dynamics AX application." For this reason I avoid the use of the .NET Business Connector. There are scenarios where the .NET Business Connector could be a logical choice over AIF services, however we don't know how long Microsoft intends to support it.
First let's start with some definitions.
AIF
AIF is an acronym for Application Integration Framework. It is the recommended integration approach (http://technet.microsoft.com/en-us/library/dd362112(AX.60).aspx See the Presentation tier (clients and external applications) section of the article.)
AIF Document Services
Document services are query-based services that can be used to exchange data with external systems by sending and receiving XML documents. These documents represent business entities, such as customers, vendors, or sales orders.
From: http://msdn.microsoft.com/EN-US/library/gg731906.aspx
AIF Custom Services
Custom services can be used by developers to expose any X++ logic, such as X++ classes and their members, through a service interface.
From: http://msdn.microsoft.com/EN-US/library/gg731906.aspx
Query-Based
The primary difference between AIF Document Services and AIF Custom Services is "query-based." Query-based means that the only operations you can perform with AIF Document Services are operations that can be performed with queries. Every document service can only expose the same "CRUD" (Create, Read, Update, Delete) service operations along with two special "find" operations:
Those of you with a database background are aware that this small list of operations provides a tremendous amount of functionality. There are very few integration operations that you cannot do with these basic operations. However, there may be a large difference between what you can do and what you should do.
To understand the appropriate use of a Document Service, we also need to discuss the last sentence of Microsoft's definition of document services. The "Document" in document services refers to an XML document, which is a little misleading because the AIF Custom Services also use XML to exchange data. The real key to understanding the document services is the fact that the document is also intended to "represent business entities such as customers, vendors, or sales orders."
That is the key here. If you want create, read, update or delete a business entity then document services are for you. If you would normally choose to use a query for the operation if you had direct access to the database then document services are definitely for you.
There are some caveats here however, and this is where the benefits of document services begin to become a little fuzzy. Let's use a concrete example. I had a recent application that required the user to be able to change the delivery address on a sales order. The proposal was to use the standard, out-of-the-box Sales Order Document Service (http://technet.microsoft.com/en-us/library/cc967401.aspx) At first glance this seems like a logical solution. The integration code would use the document service in this fashion:
1. Find- Provide the Sales Order ID to find the sales order and have the XML document returned from the database.
a. Modify the sales order by updating the delivery address on the sales order
2. Update - Provide the Sales Order ID and the Sales Order Document with the modified data.
This seems very straight forward, however let's examine what we actually need to happen and then compare it to what actually happens with the document service.
What We Want to Happen
The first thing we need to understand is the tables that are involved to change the delivery address on a sales order. Remember, the delivery address is actually associated with the sales order line (SalesLine table). To update the existing lines we will need to change the delivery address for each line. If we were in the AX Client, we would simply change the address on the header and the client code would prompt us asking if we want to update all the lines also.
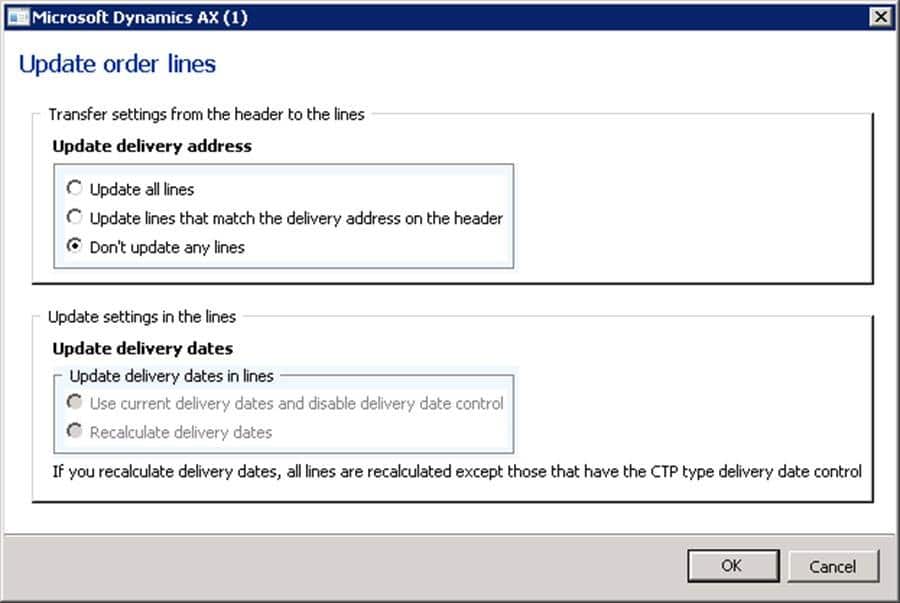
We don't have that luxury with the document service. So we are going to have to make that decision in our integration code. So now we need to update every line that needs the new delivery address.
Speaking of new delivery address, there are two possible scenarios here that we need to address. One is when a customer has previously provided the delivery address and the other is when the address is a new delivery address. In the first case we need to know the RecID for the LogisticsPostalAddress table that contains the existing address, because that is the value stored in the SalesLine.DeliveryPostalAddress field for the delivery address. In the case of a new address we need to create a new LogisticsPostalAddress record and then associate it to the customer as a delivery address and then put the RecId in the SalesLine.DeliveryPostalAddress field.
Believe it or not, unless you are storing the LogisticsPostalAddress record Ids outside of AX, the second scenario is actually the simplest when using the Sales Order document service. This is because the service query uses a view (LogisticsPostalADdressView) that will allow us to add a new record and associate it with the sales order in one step. However, for existing addresses we either need to store the AX LogisticsPostalAddress.RecId value for the address, or we need to use the CustCustomerService document service to retrieve the delivery address record ID for the customer and then use that record ID on the sales order.
You may be thinking that this same logic would have to be done with any other options besides document services, and you would be correct. The question is not the required logic, but is a query-based document service the correct tool for performing this logic.
Let's look at what happens "on the wire" as they say when you follow this logic.
1. We find the sales order.
This is a very simple call to the document service (though one could argue creating the cryptic arrays of query criteria is not simple). A small XML request is sent to AX
<?xml version="1.0" encoding="UTF-8" ?> - <SalesOrderServiceFindRequest xmlns="http://schemas.microsoft.com/dynamics/2008/01/services"> - <QueryCriteria xmlns="http://schemas.microsoft.com/dynamics/2006/02/documents/QueryCriteria"> - <CriteriaElement> <DataSourceName>SalesTable</DataSourceName> <FieldName>SalesId</FieldName> <Operator>Equal</Operator> <Value1>000753</Value1> </CriteriaElement> </QueryCriteria> </SalesOrderServiceFindRequest>
However, what we get back is a significant amount of data. I won't overwhelm you with the details but suffice it to say the request is large. The request is 487 bytes while the response is 10,166 bytes.
2. We modify the sales order lines.
This isn't really very difficult either, but it does involve iterating over all the lines and making the modifications.
3. We call the Update operation on the document service.
Once again we find ourselves passing a massive 10K file up the wire to make a minor change. We could make it smaller by removing all the unnecessary data, but that is a lot of extra work also.
Why do we have to deal with the entire sales order just to change the delivery address? Well, here is one of the main issues that one must keep in mind with document services. The main point of the document service is to exchange a document. The document is defined with an XSD and you must conform to that definition. Now, to be fair, not all of the fields are required, you can lighten the load some and in reality, we wouldn't really have to retrieve the sales order at all. If we know how to build the correct data structures to create the proper call to update a record we can pass only the correct data, include the child records we want to affect and call the update. However, many people do retrieve the record, edit it and then send back the edits for an update because it is not a small task to figure out how to get the minimum requirements met for every scenario one encounters.
Other Options
So what other options do we have? Well, we could create a custom service that is designed specifically to perform the update we are looking to perform. It could expose an operation named "UpdateSalesOrderDeliveryAddress" and it could take as a parameter a custom Data Contract such as this:
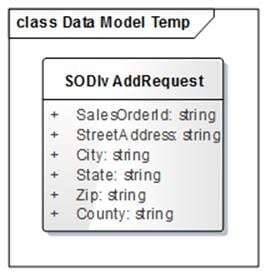
The operation could simply do all the logic necessary. It could check to see if the customer has that address already defined as a delivery address. If not, it could add it. It could then update the header of the sales order with the address identifier. It could even call the same code that the client UI calls to update the rest of the sales order based on the rules required for the operation. We could even add another parameter on the data contract that is an enumeration that specifies how the sales order lines are handled, similar to the radio buttons the UI offers.
Here is the main point that I want to make. If you have a discrete task you want to accomplish, it is best accomplished by a custom service that exposes an operation that performs that task. I make this assertion on the basis of the principles of Service Oriented Architecture and Object Oriented Design.
SOA
In Service Oriented Architecture there are several principles ( More information on SOA principles here.) that are advocated as best practices. One of those principles is Service Abstraction which basically states that a service should only expose as much information as is required to effectively use the service. All of the logic should be contained within the service and it should only require as much information as is required to accomplish the purpose of the service.
SOLID
Another best practice that is relevant is the "I" in the Acrostic "SOLID" that refers to a set of five best practices of object-oriented design (More information on SOLID). In "SOLID" the I stands for Interface Segregation Principle. This principle states "“many client-specific interfaces are better than one general-purpose interface."
Document services, by their very nature violate the principle of abstraction and the principle of Interface Segregation.
There is another problem with using document services for some discrete tasks. If you have a task that must be transactional you will almost always find document services to be inadequate. To illustrate this, let us continue with our need to change the delivery address on a sales order.
Let us assume that the new address does not exist. We can know that by finding the customer record using the Customer Document Service provided by AX. The customer service provides a complete list of all the addresses associated with the customer. If our code gets the customer document from the service, iterates over the list of addresses and doesn't find the address, it would be logical to simply add the address to the list and update the customer by calling the Update operation on the customer document service. Now the address exists, however, the address record ID is what is required by the sales order. To obtain the ID our code would call the customer service again and obtain the list of addresses with the newly added address. Now, it would again seem logical to take record ID of the last address in the list because you just added the address. But how do you know someone else hasn't added an address also?
I had this very scenario occur at a customer site. They wrote the code to add the address to the customer, re-read the customer and get the last address and use it. However, although the odds seem long, as many as four times per month someone else (or another instance of the integration) had also added an address to the same customer at the same time. The logic that assumed the last address was the one added was incorrect. So to fix the problem, the code had to be updated to iterate over the list again and compare each address to the one desired until the correct address ID was obtained.
All of this could be avoided with a custom service that exposes an operation that adds an address to the customer and returns the address ID of the newly added address.
Why Use Document Services?
If document services violate so many design best practices, should we use them at all? The answer is yes. They can be very good when performing simple "CRUD" operations on a single entity or even a list of entities. Do you want to add 1000 sales orders with no interaction? The Sales Order Service is your friend. Do you want to create customer payment records based on customer invoices? You will love the Customer Payment Journal document service. But if you want to do something that affects multiple entities, performs business logic or only requires the use of a small subset of data provided by a document service, you should probably consider using a custom service.

Under the terms of this license, you are authorized to share and redistribute the content across various mediums, subject to adherence to the specified conditions: you must provide proper attribution to Stoneridge as the original creator in a manner that does not imply their endorsement of your use, the material is to be utilized solely for non-commercial purposes, and alterations, modifications, or derivative works based on the original material are strictly prohibited.
Responsibility rests with the licensee to ensure that their use of the material does not violate any other rights.